
Why Retry Logic Corrupts Data Silently

Retries are one of the most misunderstood reliability patterns in data engineering.
They look harmless.
They often make things worse.
The Intuition That Fails
The logic sounds reasonable: If something fails, retry it.
This works for:
Read operations
Idempotent writes
Stateless requests
But most data pipelines are stateful.And retries don’t understand state.
A Real Production Failure Pattern
Consider this simplified pipeline:
Read event from source
Transform
Write to target
Acknowledge success
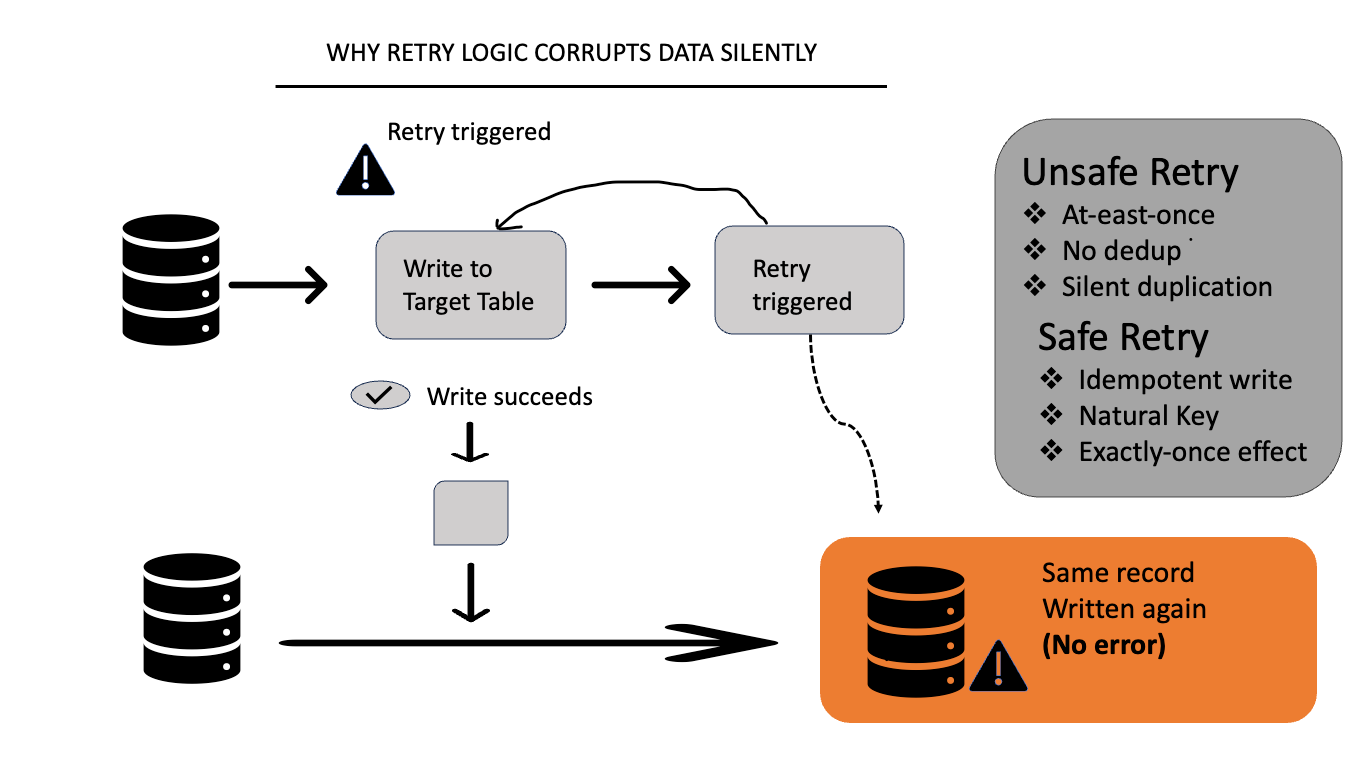
Now imagine this happens:
Step 3 succeeds
Step 4 (ack) fails due to a timeout
From the system’s point of view:
“The write may have failed.”
So it retries.
The result:
Same record is written again
No exception is raised
Data is now duplicated
This is the worst kind of failure: silent and permanent.
Let me give you one simple example
The “looks safe” version
def process_event(event):
write_to_table(event)
send_ack(event.id)What the developer assumes:
First, data is written.Then, an acknowledgment is sent.If something fails, it will fail loudly
What’s actually happening:
write_to_table() modifies state (database)
send_ack() is a network call (Kafka, API, queue, etc.)
These two operations are not atomic
Once the write succeeds, the system state is already changed.
2.Adding retries (where things go wrong)
@retry(times=3)
def process_event(event):
write_to_table(event)
send_ack(event.id)This looks harmless even responsible.
Intent:
“If something transient fails, just retry.”
But retries don’t understand which part failed.
Why Monitoring Doesn’t Catch This
From an operational perspective:
Jobs succeed
No alerts fire
SLAs look healthy
But analytically:
Counts inflate
Metrics drift
Trust erodes
Retries turn partial failures into data corruption.
What Actually Makes Retries Safe
Retries are safe only when idempotency is guaranteed.
Examples:
Deduplication using a natural key
Exactly-once semantics enforced at the sink
Write-once patterns with conflict detection
Example:
INSERT INTO orders (...)
VALUES (...)
ON CONFLICT (order_id) DO NOTHING;Or:
if not exists(event.id):
write(event)Now retries become harmless.
The Lesson
Retries don’t fix failures.
They move failures around.
Senior engineers assume:
Writes may partially succeed
Acks may lie
Timeouts don’t mean failure
So they design for re-execution.
Overall
Retries are easy to add.
Data corruption is hard to notice.
If a pipeline can’t be safely re-run,
it isn’t reliable
it’s just been lucky so far.
If you’ve seen pipelines “succeed” while the data quietly drifted, you’re not alone.
I’ll keep breaking down real production failure modes and how to design around them subscribe if this kind of thinking is useful in your work.